超入門! すべての医療従事者のためのRStudioではじめる医療統計 第2版


医療統計のテキスト。どういうときにどういう解析が使えるのか、実際にソフトウエアを動かしながら具体的にわかる。
ベースになるソフトウエアは、RとRStudio。Rは無料の統計ソフト。RStudioはそれが簡単に使えるようになるフロントエンドで、これも無料。いずれも専門家向けとして信頼されている。
医療関係でよく使われる統計ソフトにはSPSSもあるが、法人契約だけだし、高額だ。学校を卒業したり転職したら、使えなくなってしまう。Rを学んでいたらそのようなことがない。
Rは歴史のあるソフトで、ちょっと仕様に古くささが残る。この本では、それを現代化する追加パッケージtidyverseも使われている。tableoneなど便利なパッケージもいくつか使われる。
第2版の改訂では、紙面が大幅に増量された。データクリーニング、グラフでの日本語の処理やグラフの保存法が詳しくなり、予測モデル、傾向スコア分析の章が新規に加わった。全体が2つのパートに分割され、パート1は基本的な項目、パート2は発展的な医療統計が含まれる。
解説は実際的で、すぐに応用できる。一方で、読者には基本的な統計学は知っていることが期待されていて、その詳しい解説は省かれている。
サンプルのスクリプトやデータは本のサイトからダウンロードできる。



内容を見ていこう。
全体が物語の仕立てになっている。主人公のAくんは後期研修医で、上司からいわれて学会発表することに。電カルのデータを解析してモノにしようと思い立ったが、SPSSとかはないので無料のRにしようとなった。データ処理や解析方法を学びながら、論文発表までこぎ着ける。
著者略歴をみると、登場人物は具体的なモデルのフュージョンなのかもしれない。ちなみに、Rを勧めてもSPSSにされてしまうのは、評者も経験ある。

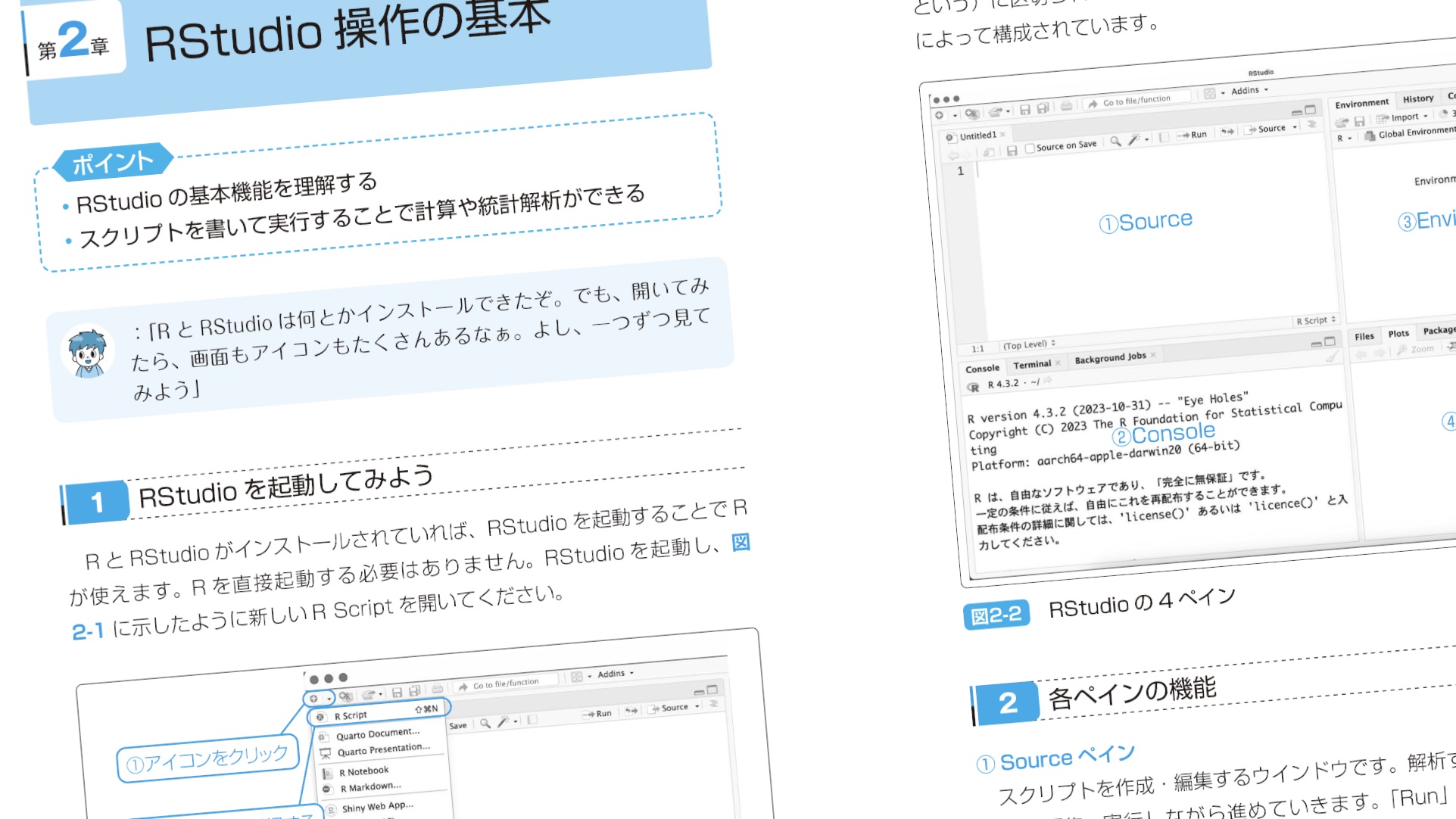
最初は、RとRStudioのインストールから、RStudioの使い方。スクリーンショットがたくさん使われていて、本にあるとおりやればうまくいく。
この改訂で、ありがちなトラブルへのサポートが「Column」として追加された。たとえば、関数名の競合。ライブラリーをいろいろ追加していくと、名前の同じ関数が複数有効になってしまい、予期しない挙動を起こすことがある。解決策がいくつか提示されている。もっとも、トラブルの原因に気づけるかどうかが先なので、そのあたりのコツもあるとよかったかも。

この改訂で強化されたことが、tidyverseを使ったデータフレームの操作だ。
まず、ロング型とワイド型の変換。人がExcelなどを使ってデータを整理すると、たいていWide型になる。しかし、tidyverseの扱うのはロング型だ。そのため、この変換は必須だ。
もうひとつが、データフレームの結合。複数のデータベースを名寄せして組み合わせる、月ごとのデータをつなげて長期間のデータにまとめるなど、必要になることは多い。


tidyverse以外に便利に使われているのが、tableoneパッケージだ。データを論文の「表1」のようにまとめてくれる。ボストン在住の日本人の研究者が開発した。

グラフの描画では、日本語の文字化け対策が加わった(初版では本のサイトにあった)。グラフに使われるggplotは、デフォルトのままだと日本語が文字化けするが、ちょっとした設定変更で直る。グラフをスクリプトで画像ファイルに保存する方法も加わった。

データが整い、グラフで概要が見えてきたら、解析だ。群の数と分布にあわせて、手法を選択できるようになっている。手法の選択のための表やダイアグラムが便利だ。
一般的な統計学の入門書だと2群の比較で終わってしまいがちだが、医療関係では3群以上になることも少なくない。本書では、多重検定や一元配置分散分析、重回帰・ロジスティック回帰まである。
なお、2群の比較で、分布が正規性を外れたらウィルコクソン順位和検定(マン・ホイットニーのU検定)をすることになっていた。サンプルデータは「分布が偏っている+等分散(F検定で確認した)+サンプルサイズが大きいが差が2倍くらい」という状況だった。下のページを参考に、サンプルデータと条件を合わせてシミュレーションしてみると、どうやらウエルチのt検定が安全だったかもしれない。
参考(元群馬大学教授・青木 繁伸氏のサイトから):
- 二群の平均値(代表値)の差を検定するとき>3.2. 歪みのある分布の場合>3.2.2. サンプルサイズが約 1:2 の場合

パート1からパート2にかけて、論理的な順番が前後しているかもしれない。一般的な統計学のテキストにもある話題をパート1、発展的な話題をパート2にするなら、パート2に入っているデータ作成や相関はパート1でいいし、パート1に入っている生存曲線はパート2のほうがいい。
ここではそんな順番でみてみる。
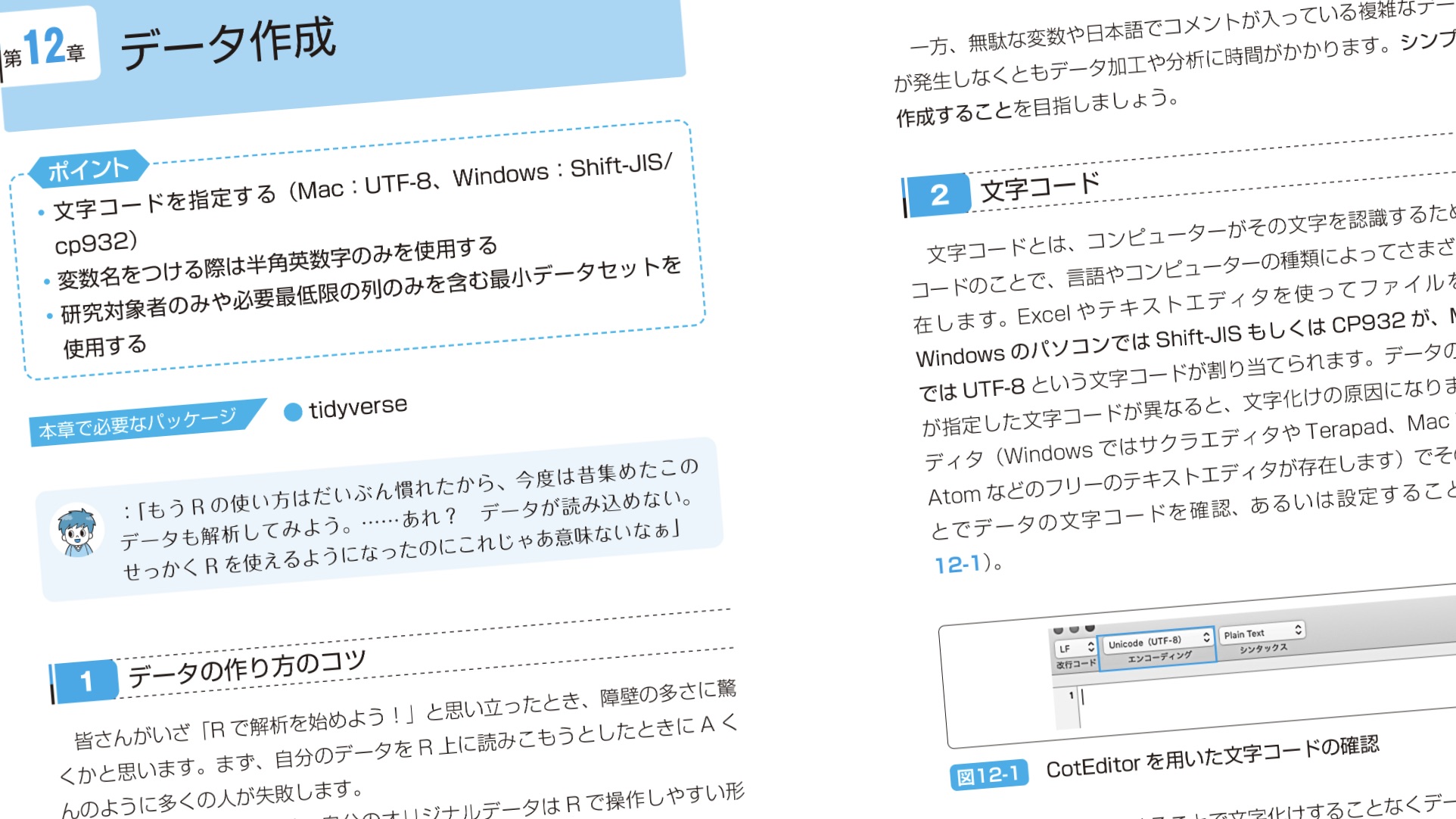
既存のデータを使っているとありがちなトラブルが、データの読み込みの不具合。それも、日本語の文字コードのミスマッチやデータ型の指定ミスだ。
本書には説明がないが、これをうまくやりこなすには、RStudioの「Import Dataset」を使うと簡単かもしれない。読み込みのスクリプトのプレビューができるので、それをコピペして使える。困ったら試してみよう。これは『Rをはじめよう生命科学のためのRStudio入門』に詳しい。
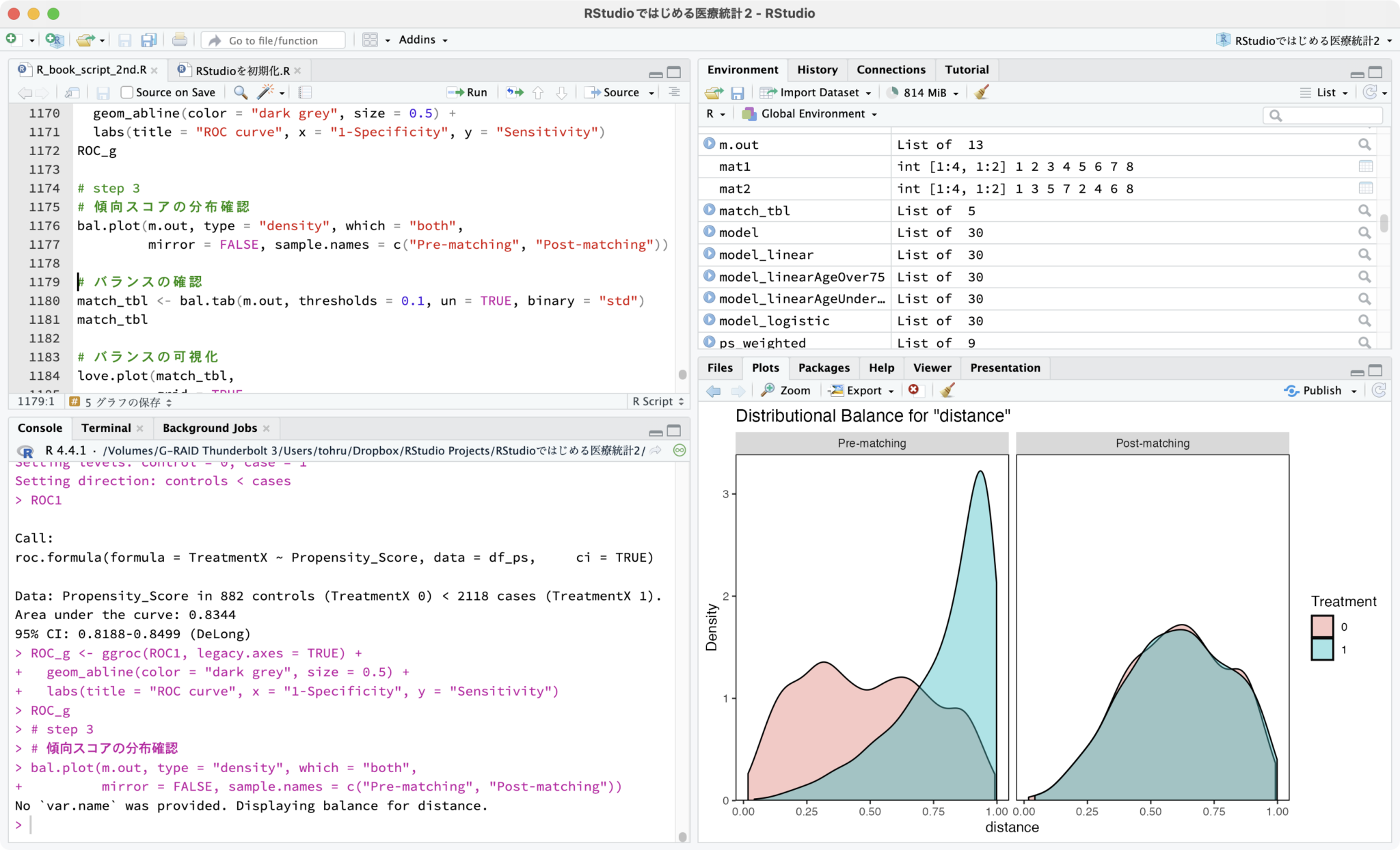
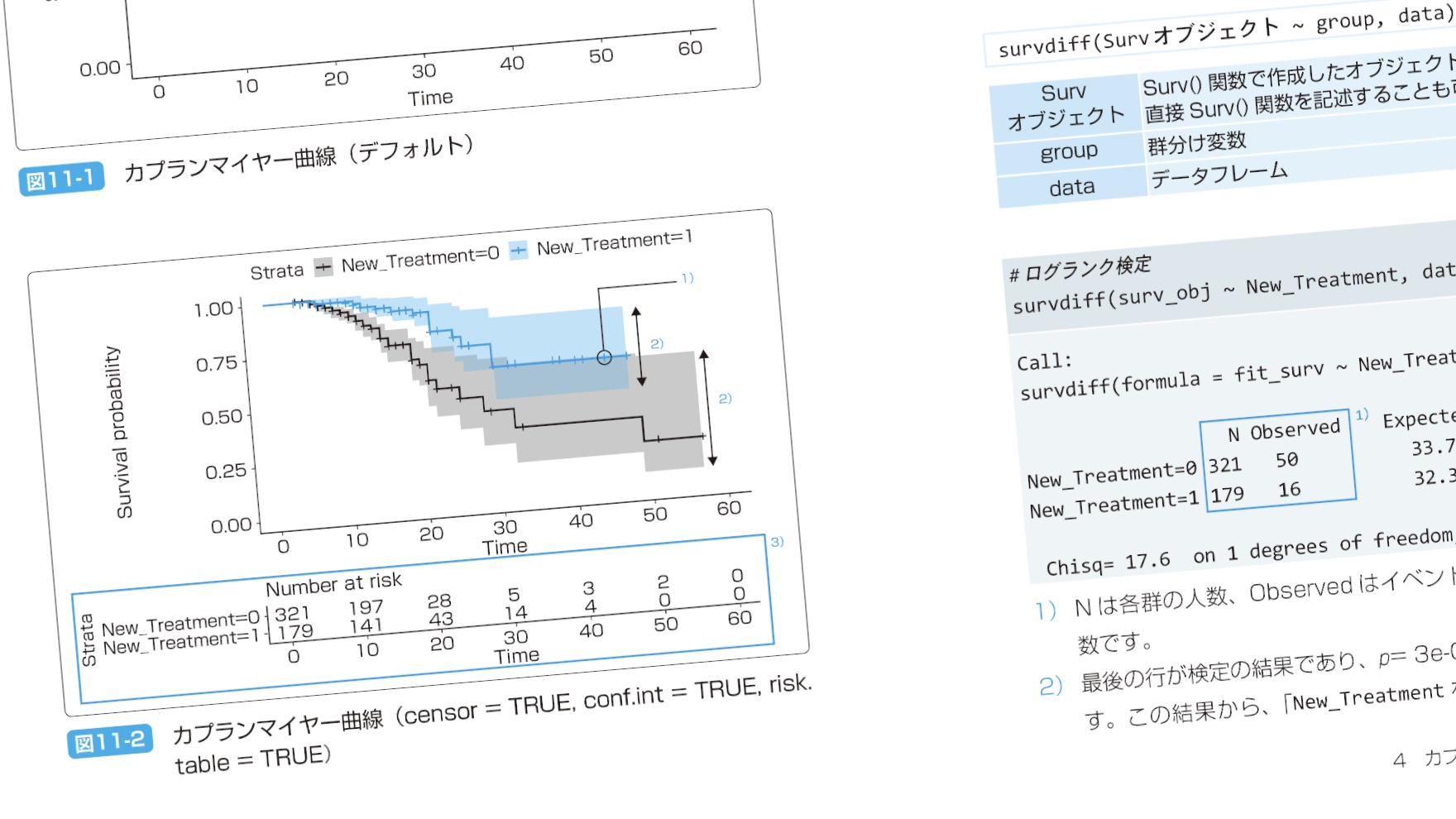
生存時間分析は、いかにも医療統計だ。
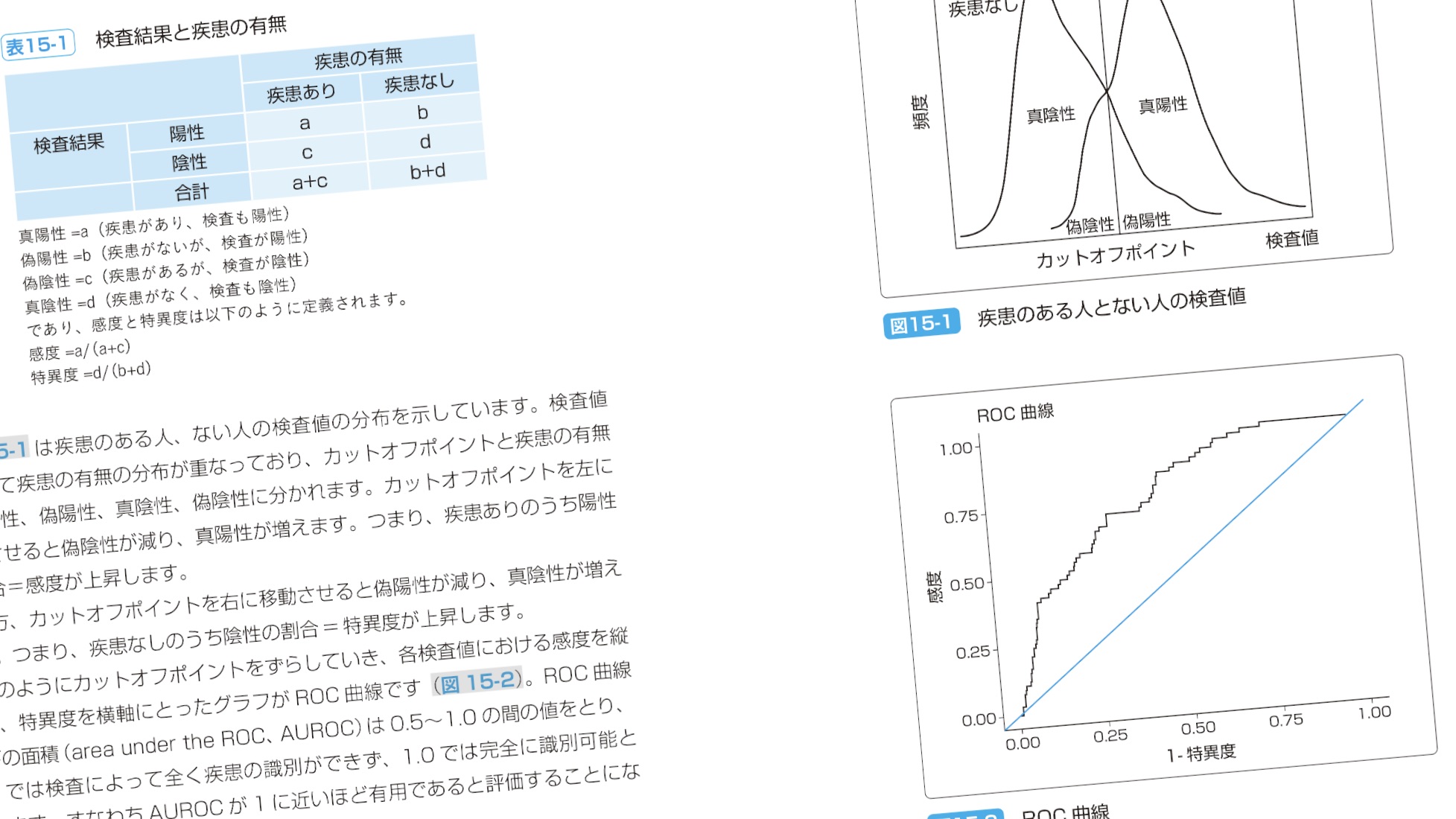
ROC曲線のところもよく読もう。COVID-19のパンデミックで、検査に関する議論がたくさん出てきたのを覚えているだろう。それを理解できる。
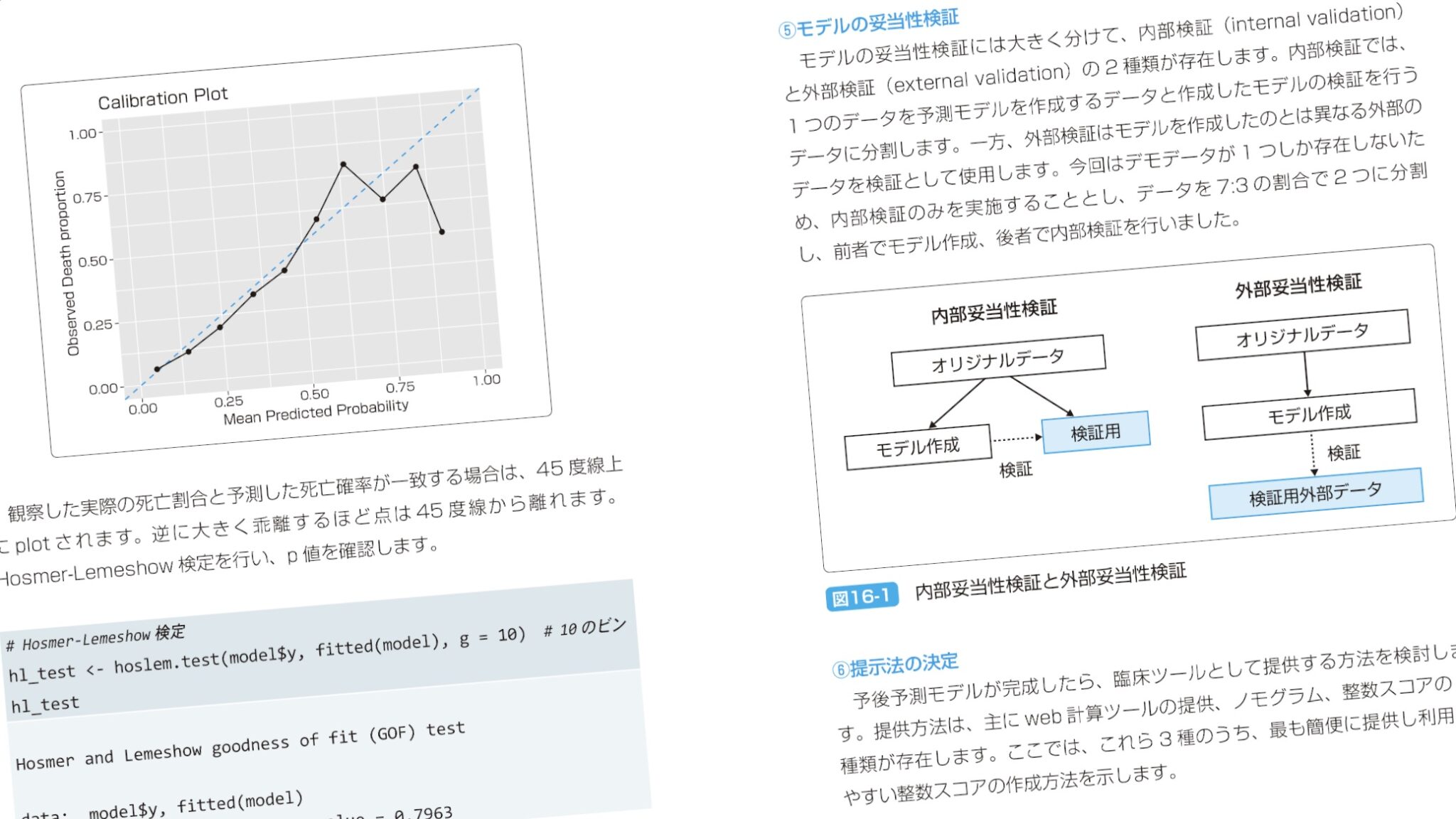
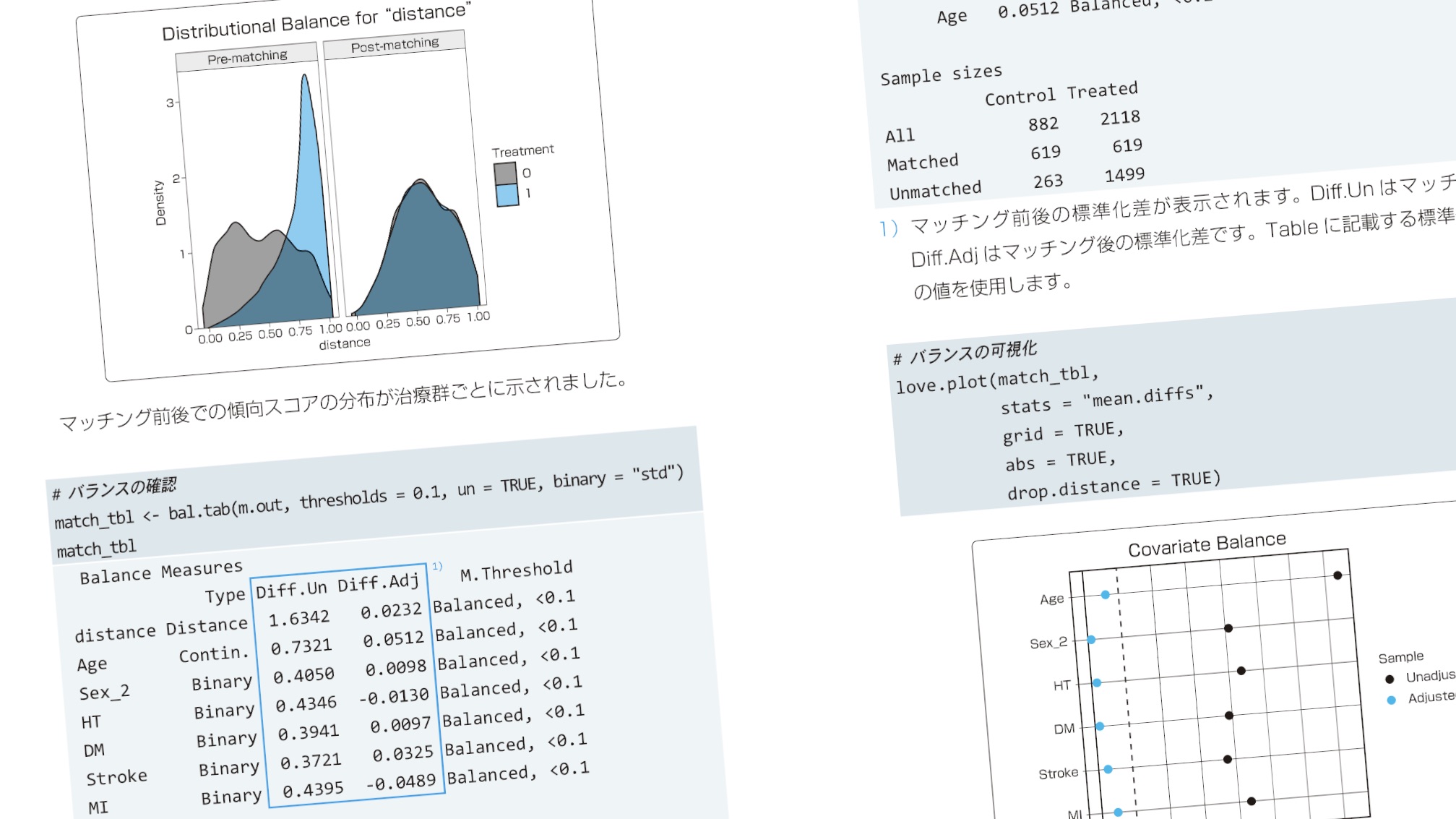
今回追加されたのが、予測モデルと傾向スコア分析。専用のパッケージを使う。
「あとどのくらい生きられますか?」「その治療を受けたらどのくらい効きますか?」といった質問への答えにエビデンスを与えられるだろう。
詳しい話は別の本を読んだ方がいいと思うが、ちょっと試しにやってみるのもよい。総務省統計局のサイトに高校生向けの教材があるから、それもチェックしたら感じを掴めるかもしれない。
「高等学校における「情報II」のためのデータサイエンス・データ解析入門」
紙面画像の本記事への使用について金芳堂様より許諾いただきました(2024年9月4日)。